


Похожие запросы (Related Questions, далее RQ) - это вопросы которые относятся к вашему поисковому запросу, и на которые возможно вы бы хотели узнать ответ.
RQ становятся все более распространенной функцией SERP с момента их появления в 2016 году. Свежие данные из Mozcast показывают, что RQ имеют около 49% запросов. Хоть данные из буржунета, скоро это ждет и нас.
Этот блок, привязанный к алгоритмам машинного обучения Google, показывает вопросы, связанные с первоначальным запросом пользователя. Например, если вы введете «seo» в google.com.ua, вы увидите следующее:
Изначально прием этой функции среди сообщества SEO был несколько негативен - возможно, потому, что многие рассматривали его как еще одну функцию, предназначенную для снижения CTR органики, но за последние два года все больше людей определяют ценность использования этих данных для дополнения своей seo стратегии.
Как использовать эти данные
3 способа использования полученных данных:
Вы можете использовать вопросы для создания часто задаваемых страниц (FAQ).
Мы использовали эту тактику на нескольких сайтах и обнаружили, что часто задаваемые вопросы становятся важным ресурсом для клиентов в их понимании услуги или товара.
Использование информации для настройки таргетинга через заголовки объявлений, или для создания новых страниц.
Актуальные вопросы, которые задают пользователи, связанные с вашими ключевыми словами, можно легко найти с использованием данных RQ, которые могут помочь в создании контента для вашего сайта и предоставлении дополнительной информации пользователям.
Также использование RQ увеличивает шанс попадания в блок ответов.
Отформатировав ответы на эти вопросы в виде списков или пошаговых руководств, можно получить нулевую позицию. Это повысит CTR вашего сайта и поможет дать вашему сайту больше авторитета в выбранном вами вопросе.
Сбор похожих запросов Google
Независимо от того, как вы собираетесь использовать похожие запросы, первым шагом будет сбор данных. Существует несколько способов сделать это.
Сбор вручную
В случаях, когда вы анализируете несколько ключевых слов, ручной сбор является лучим подходом - просто загуглите свои ключи и посмотрите, активирована ли функция RQ. Если да, просто копируем их в удобное для вас место для дальнейшего анализа и использования в написании контента.
Screaming Frog
Одна из лучших и наиболее неиспользуемых функций Screaming Frog - это выборочная экстракция. Она позволяет нам извлекать любую информацию из сканируемых веб-страниц в автоматическом режиме.
Стоит напомнить, что парсинг гугла технически нарушает условия и положения Google. Но этим занимаются различные сервисы, которые вы используете ежедневно, поэтому я уверен, что они нас простят. Мы стремимся улучшить качество контента и веб-сайтов в конце концов)
Тем не менее если вы используете стандартные настройки лягушки, то очень быстро словите капчу, и экстракция не будет работать. Таким образом, важно, чтобы вы укрощали лягушку.
Настройки которые использую я, must have:
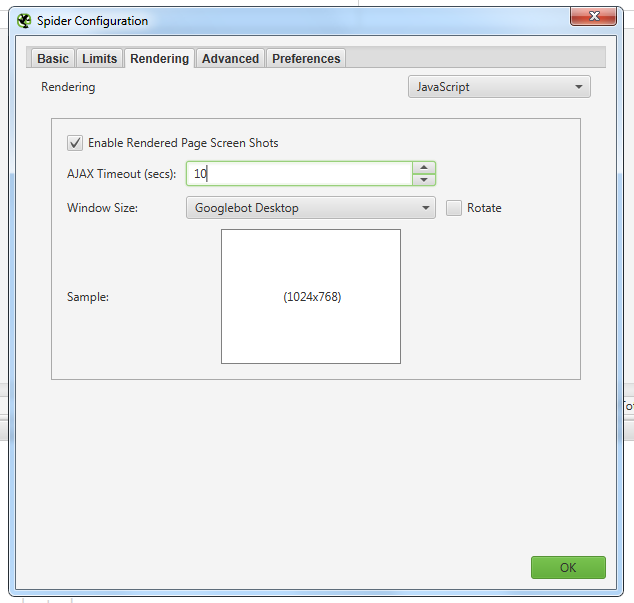
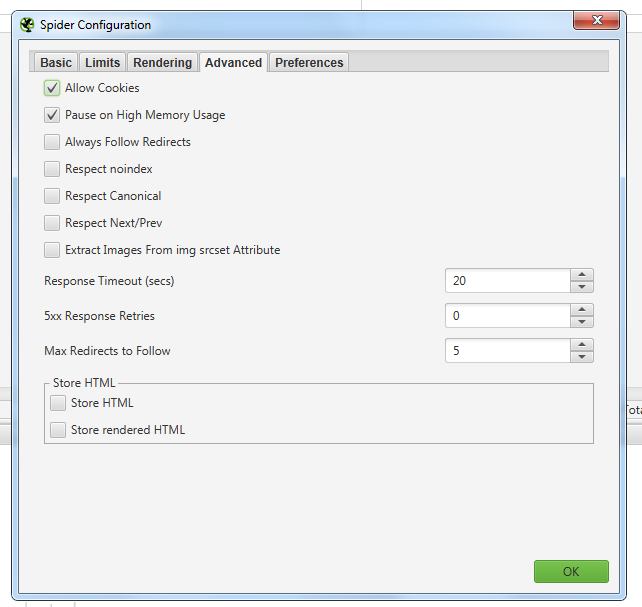
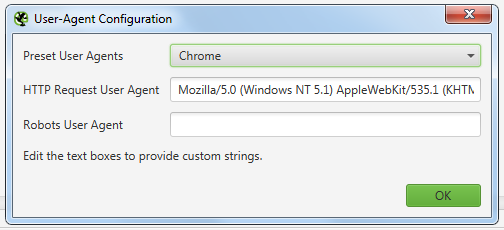
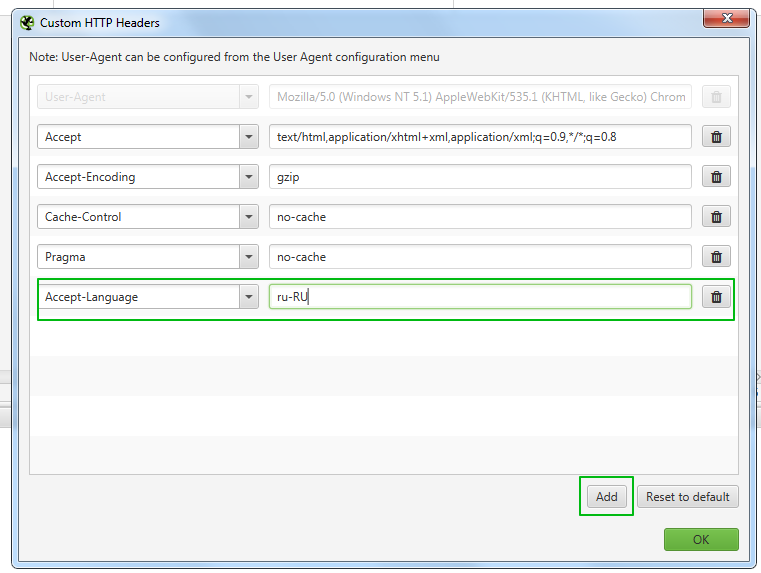

Затем вам нужно будет создать список URL-адресов и ключей, которые вы хотите проверить.
У нас есть два способа собрать ключи.
Первый. Этим способом мы соберем ключи которые точно имею блок "Похожие запросы". Переходим в Ahrefs >> Анализ ключевых слов >> Проверяем ключ >> Фразовое совпадение. После чего ставим фильтр Related questions:

Второй. Использование запросов из СЯ. В этом случае количество запросов с наличием блока RQ будет около 30% (зависит от тематики), да и сам парсинг растянется.
Погнали дальше.
Мы собираемся генерировать наши URL-адреса, используя Excel. Должны прийти примерно к следующему:

Как?
В первом столбце введите версию Google, которую вы хотите использовать (например, https://www.google.com.ua), добавленную с параметром поискового запроса (/search?q=).
Второй столбец должен содержать ваши поисковые запросы. Учитывая, что они станут частью URL-адреса, вам нужно заменить пробелы символом «+» и избежать любых других специальных символов.
Затем требуется третий столбец для любых других параметров, которые вам нужны, например, для местоположения. На хабре есть неплохая статья на эту тему.
И наконец, четвертый столбец который должен все это объединить, используйте для этого формулу =$A$1&B1&C1.
Следующее, что нам необходимо сделать, это показать Screaming Frog область парсинга. Для этого мы гуглим запрос в котором точно есть блок "Похожие запросы".
Щелкните правой кнопкой мыши по одному из вопросов >> просмотреть код. После чего копируем XPath запрос данного блока:

После чего вставьте полученный код в Screamign Frog >> Configuration >> Custom >> Extraction:

Теперь вы можете импортировать свой список URL-адресов в лягушку, запустить обход и просмотреть полученные вопросы, экспортировав полученный результат:

Парсинг поисковых запросов Google из блока "Похожие запросы" может быть отличным способом узнать, какую информацию пользователи ищут. Добавление контента который будет отвечать на "Похожие запросы" поможет сделать ваши страницы качественными и, что более важно, полезными для ваших пользователей.


Владимир
12.09.2018Что это за плагин на скрине? Типо выделил текст и оно предлагает тебе "Copy Xpath"
admin
12.09.2018Это консоль разработчика Chrome. Правой кнопкой мышки на сайте >> Просмотреть код >> Правой кнопкой мыши на необходимом элемента и там будет меню которые видно на скрине
Павел
12.09.2018Сделайте возможность ставить звездочки статьям
А то от такого материала появляется желание лукас поставить, а некуда(
admin
13.09.2018Окей, на днях прикручу. А пока можно расшарить в соц сети)))
Александр
13.09.2018А можно подробнее, как импортировать УРЛ и Экспортировать полученный результат?
admin
13.09.20181. Открываем лягушку и выбираем режим - http://joxi.ru/82Qk8vOcjzVkdr
2. Копируем полученные урлы из екселя - http://joxi.ru/p27nwVbUo7nXXm
3. Вставляем в лягушку - http://joxi.ru/gmv0EKbTLEdayA
4. Настраиваем как в статье
5. Запускаем парсинг
6. Экспортируем через кнопку - http://joxi.ru/n2YQEjZsoQ7l72
Александр
13.09.2018Спасибо за ответ и статью)
Регина
15.09.2018XPath кстати не такой как на скрине копируется вот такое
//*[@id="_D-icW6yhNMTRrgSwlq7YCA9"]/div/div[2]/div[1]/div[2]/div
Может дополнительно в хроме что-то необходимо устанавливать?
Или плагин для копирования XPath
admin
17.09.2018Это плюс знаний XPath. Блок "Похожие запросы" может находится и в низу SERP, из за чего я модифицировал код парсинга.
Не хотел усложнять статью, можете использовать тот который у меня на скрине, только заменив класс блока.
Ruslan
13.01.2020Влад, привет.
На какой класс блока менять?
Копирую XPath для двух Related Questions по одному запросу:
//*[@id="_t-0cXsWlIoGKrwTPppioCg26"]/div
//*[@id="_t-0cXsWlIoGKrwTPppioCg50"]/div
Если задать новый запрос, XPath имет другой вид:
//*[@id="_ku8cXv26GcP3qwH1j76YAw27"]/div
Ruslan
13.01.2020Для примера код:
What is domain with example?
Vladislav
14.01.2020Попробуйте //div[*]/g-accordion-expander/div/div , должно получится http://joxi.ru/brRMJWWuYQOLLA
lord
21.01.2019как парсить динамически подгружаемый блок? http://file.sampo.ru/kd5vg4/
Vladislav
21.01.2019Какой запрос использовали?
lord
21.01.2019блок появляется после перехода на сайт
Vladislav
21.01.2019В таком случае лягушка не поможет